Project Aims & Objectives:
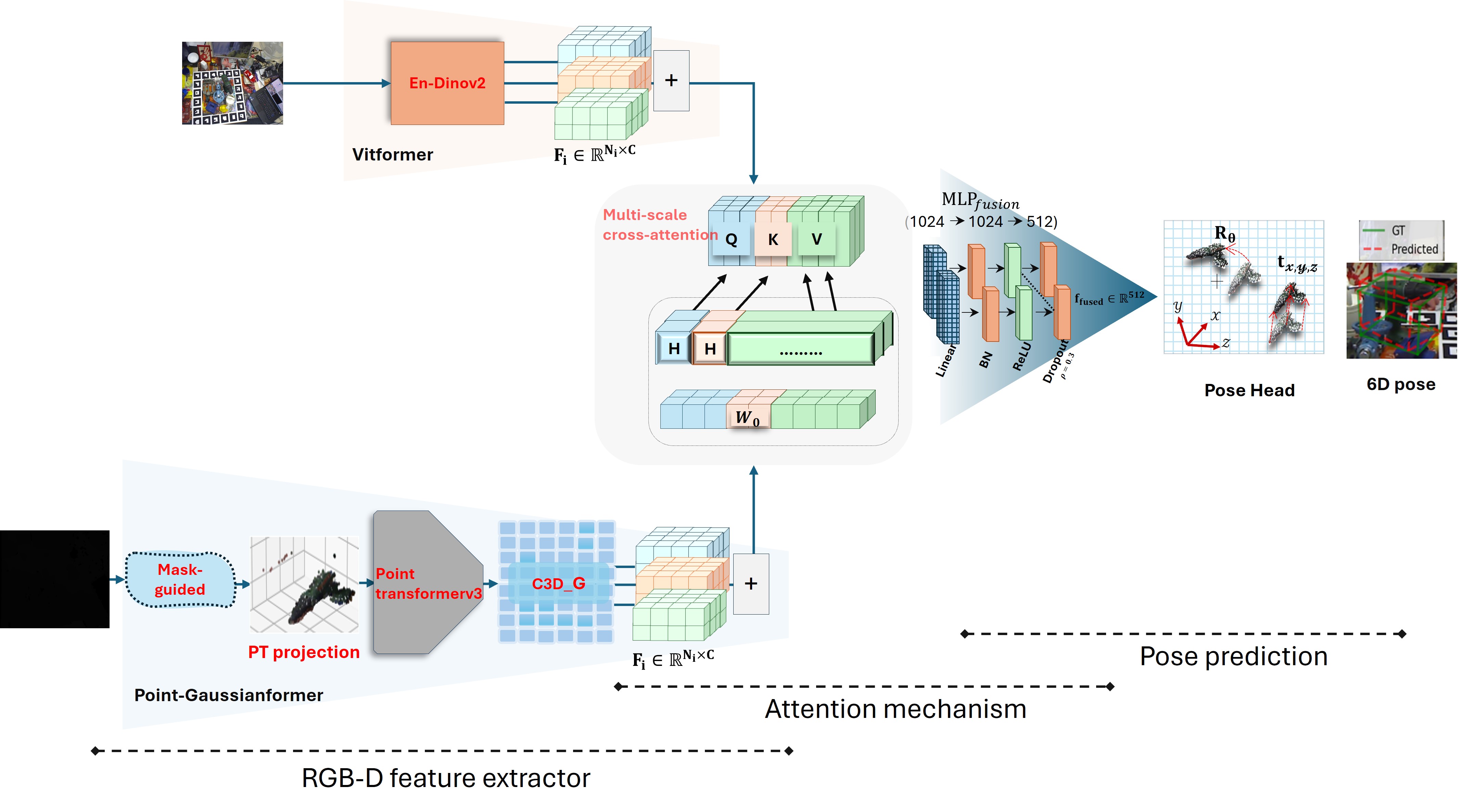
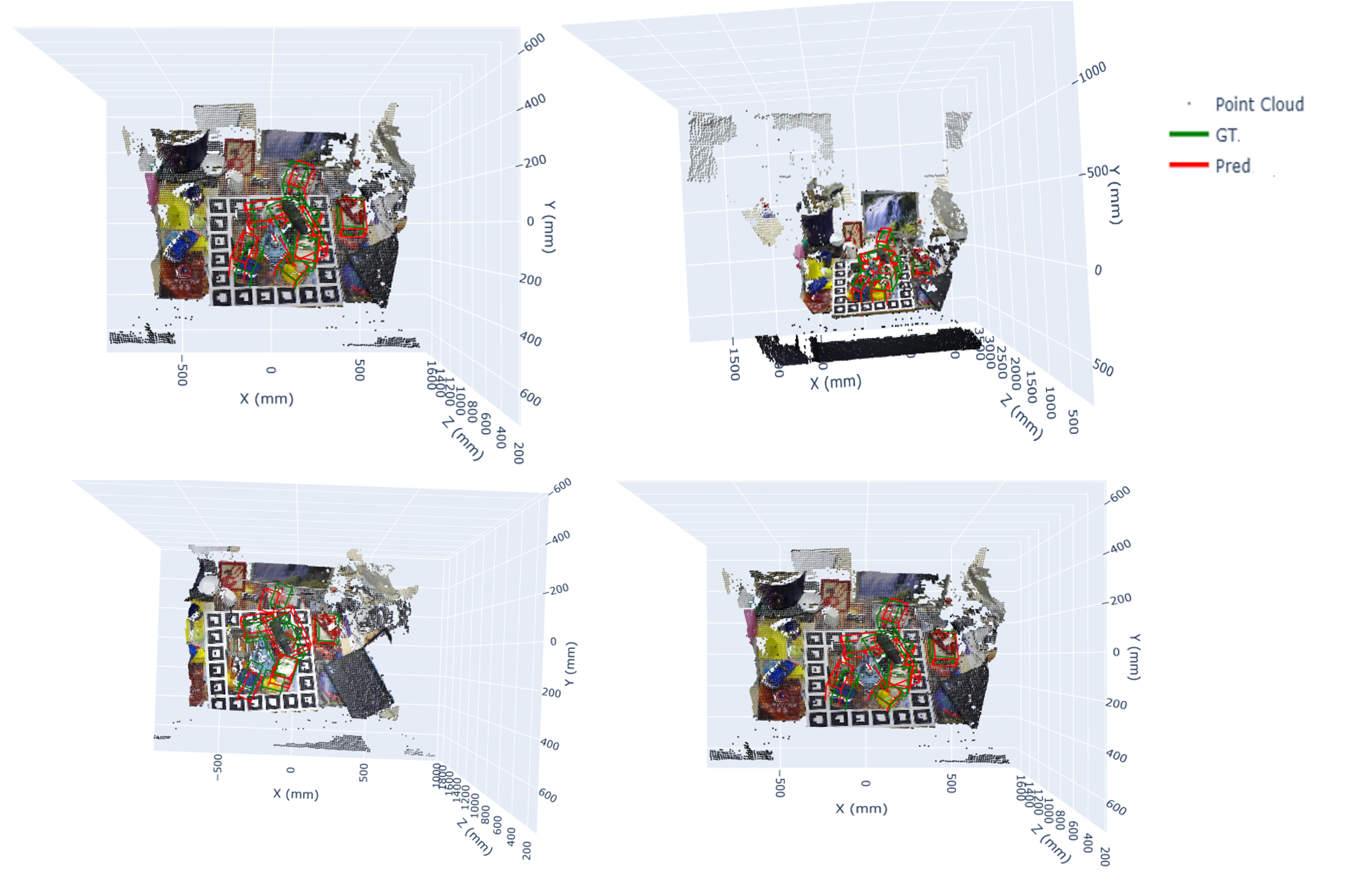
The estimation of 6D pose from RGB-D data remains challenging due to occlusions, textureless objects, and depth noise. In this work, We introduce a novel architecture to calculate precisely the 6DoF object pose from a single RGB-D image. Unlike existing structures that rely on direct regression & convolution based pose estimation as well as heavily depend on large model training, our vision based dual stream approach addresses this challenging task using hybrid multi modal fusion architecture combining self-supervised vision transformers (DINOv2) and attention based point cloud processing using C3G (Compact 3D Gaussian representations integrated with Point Transformer V3). The DINOv2 approach provides robust semantic understanding without requiring fine-tuning of visual backbone, while Point Transformer V3 employs vector attention mechanisms to model complex 3D geometric patterns from depth point clouds. Moreover, we present a mask guided point cloud extraction approach that concentrates processing on object relevant regions while filtering out background noise. The model’s efficacy is demonstrated by the experimental results on the LineMOD-Occluded dataset over RDPN SOTA benchmark, which show that our network requires substantially fewer trainable parameters than fully-supervised alternatives while achieving competitive performance and notable improvements with ADD, ADD(S) metric, rotation error, and translation error. Self-supervised learning and attention based geometric reasoning together provide new era for data efficient 6D pose estimation.
Repository
Project Aims & Objectives:
•Aggregates AI updates from curated high-quality sources • Filters noise • Adapts to personal preferences • Summarizes intelligently • Allows feedback (thumbs up / thumbs down style) • Improves over time using an agent-based backend
Repository
Project Aims & Objectives:
we run the LLM fine-tuning loop on the instruction dataset. We demonstrate how fine-tuning can improve LLM performance while following instructions.
Repository
Project Aims & Objectives:
we run the LLM fine-tuning loop on the email spam or not spam(ham) dataset. We demonstrate how fine-tuning can improve LLM performance in the classification tasks.
Repository
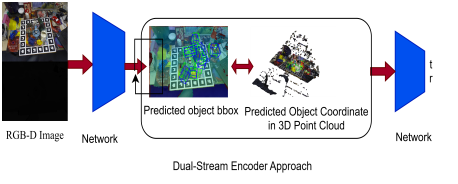
Project Aims & Objectives:
VLM6D, a novel dual-stream architecture that leverages the distinct strengths of visual and geometric data from RGB-D input for robust and precise pose estimation. Our framework uniquely integrates two specialized encoders: a powerful, self-supervised Vision Transformer (DINOv2) processes the RGB modality, harnessing its rich, pre-trained understanding of visual grammar to achieve remarkable resilience against texture and lighting variations. Concurrently, a PointNet++ encoder processes the 3D point cloud derived from depth data, enabling robust geometric reasoning that excels even with the sparse, fragmented data typical of severe occlusion.

Repository
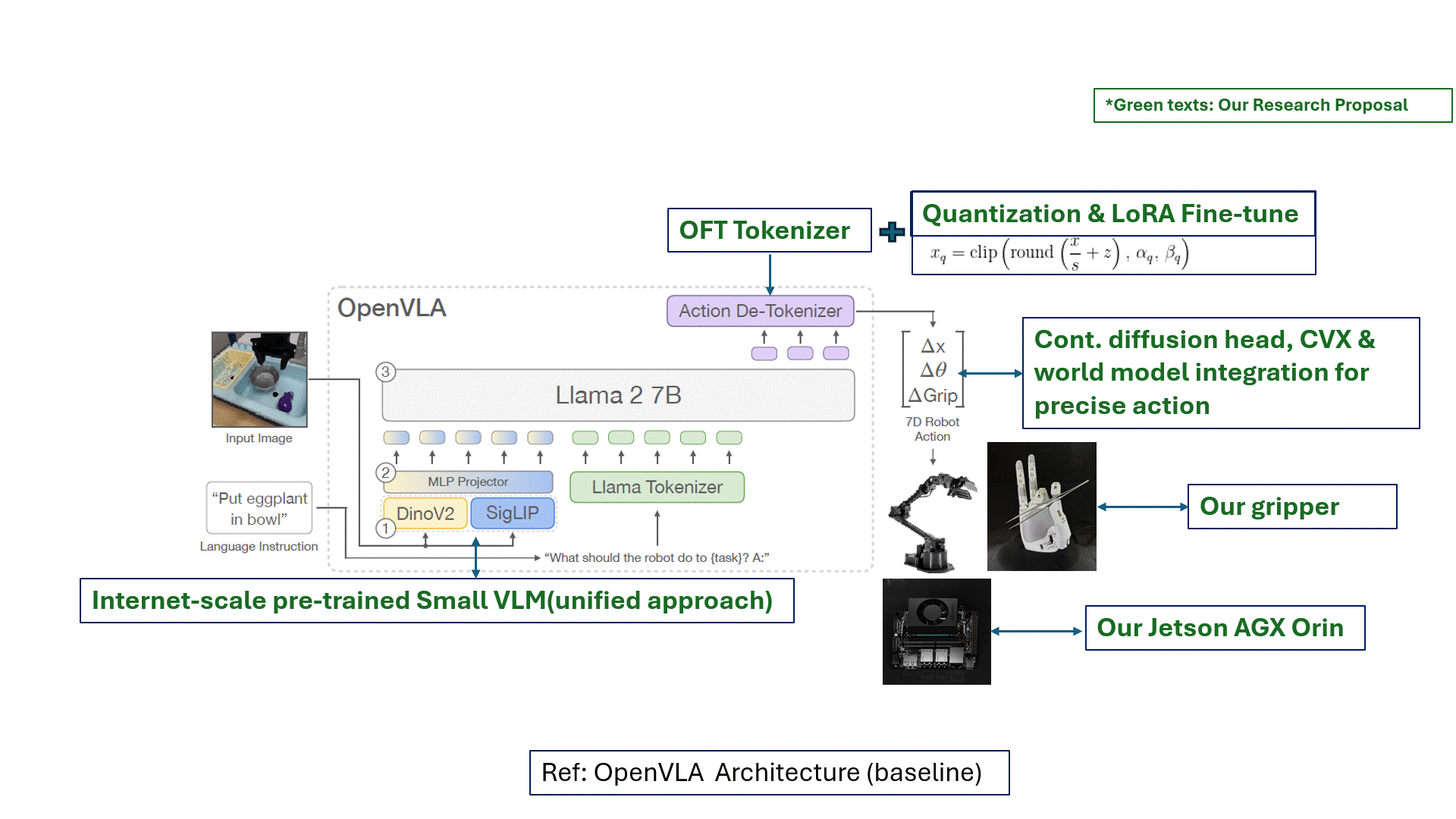

Project Aims & Objectives:
OpenVLA 모델을 파인튜닝하고, 추론 속도 향상, 스케일링 특성 개선, 제로샷 일반화 성능 및 장기 시퀀스(장시간 작업) 수행 능력을 강화하기 위한 고성능·경량화 아키텍처를 설계한다. 모델 기반 및 시뮬레이션 기반 접근을 결합한 SOTA 수준의 Efficient-VLA 네트워크를 구축하고, 벤치마크 평가를 수행하여 ACCV 2026(일본 오사카)에 논문을 제출한다. 또한, Sim-to-Real 및 Real-to-Sim 전이 학습 기법을 활용하여 5지(5-finger) 로봇 그리퍼와 NVIDIA Jetson AGX Orin 플랫폼에 비전-언어-행동(VLA) 모델을 적용한다. 다중 센서 융합을 통해 로봇 인지 및 조작 데이터를 대규모로 확장하고, 이를 기반으로 CVPR, ICCV, ECCV 등 최상위 국제학회 및 저널에 연구 성과를 발표한다.
